
[P1] クラフトバンド工作のためのデザイン支援システム

[P2] パッチ合成に基づく詳細な動きを保持した流体の流れの変形

[P3] 3D プリンタ埋め込み光ファイバー型導光路を用いたアクティブマーカによる動的プロジェクションマッピング゙

[P4] インタラクティブな貝殻の手続き型モデリング

[P5] 多重重点的サンプリングを用いた蛍光物質のスペクトラルレンダリング

[P6] イラストスタイル画像への顔特徴の反映による似顔絵生成
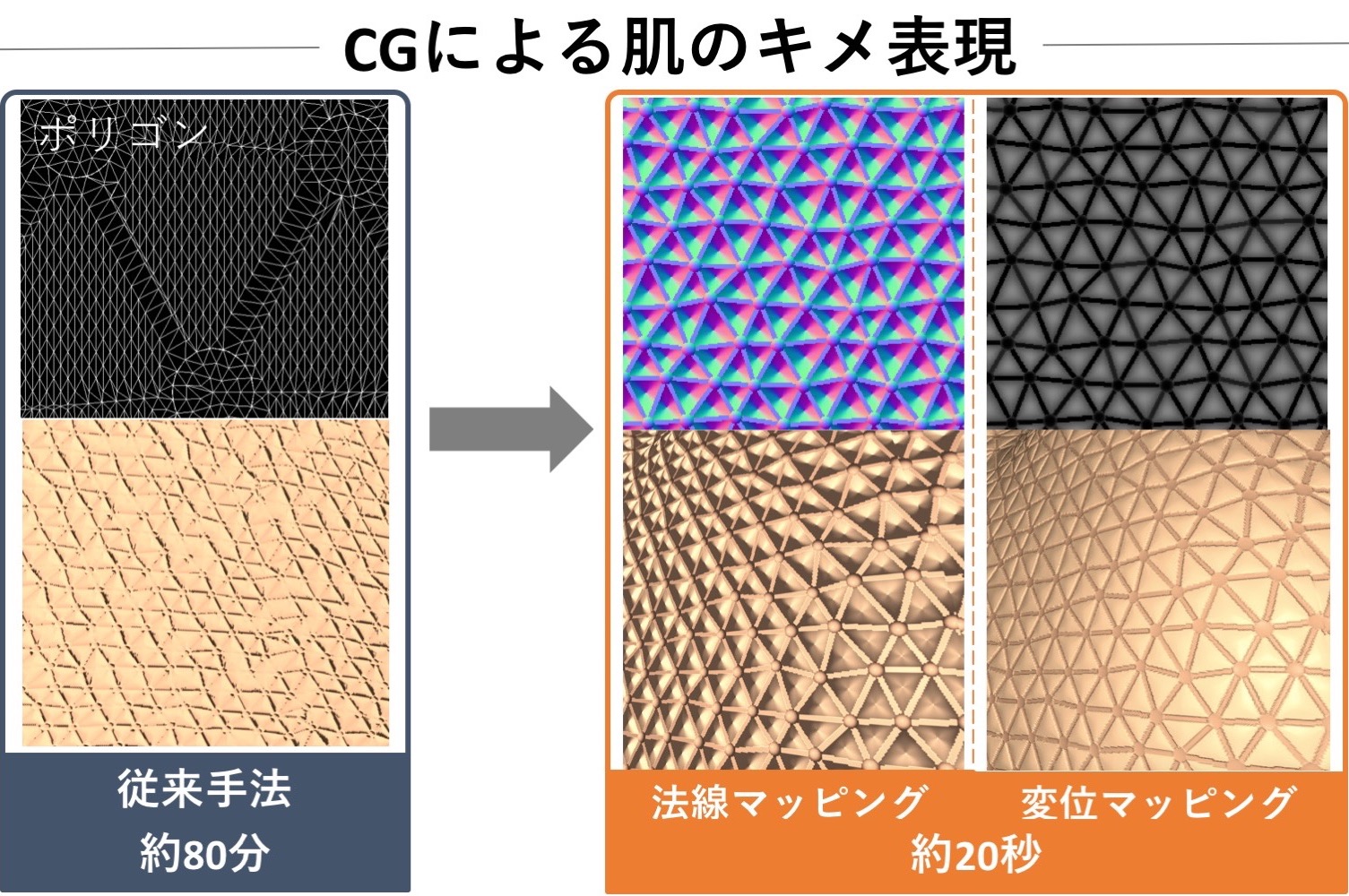
[P7] 肌微細構造のCG表現の高速化

[P8] 画素ごとの編集量を利用したメトロポリス光輸送法による効率的再生成法

[P9] 様々な天空照明条件で変化するカラーパレット

[P10] CG制作における作業過程のモデル化に関する検討

[P11] お絵描きi-Can / "Toyota City Creation" : お絵描きで乗り物三次元CGを作成するコンテンツ
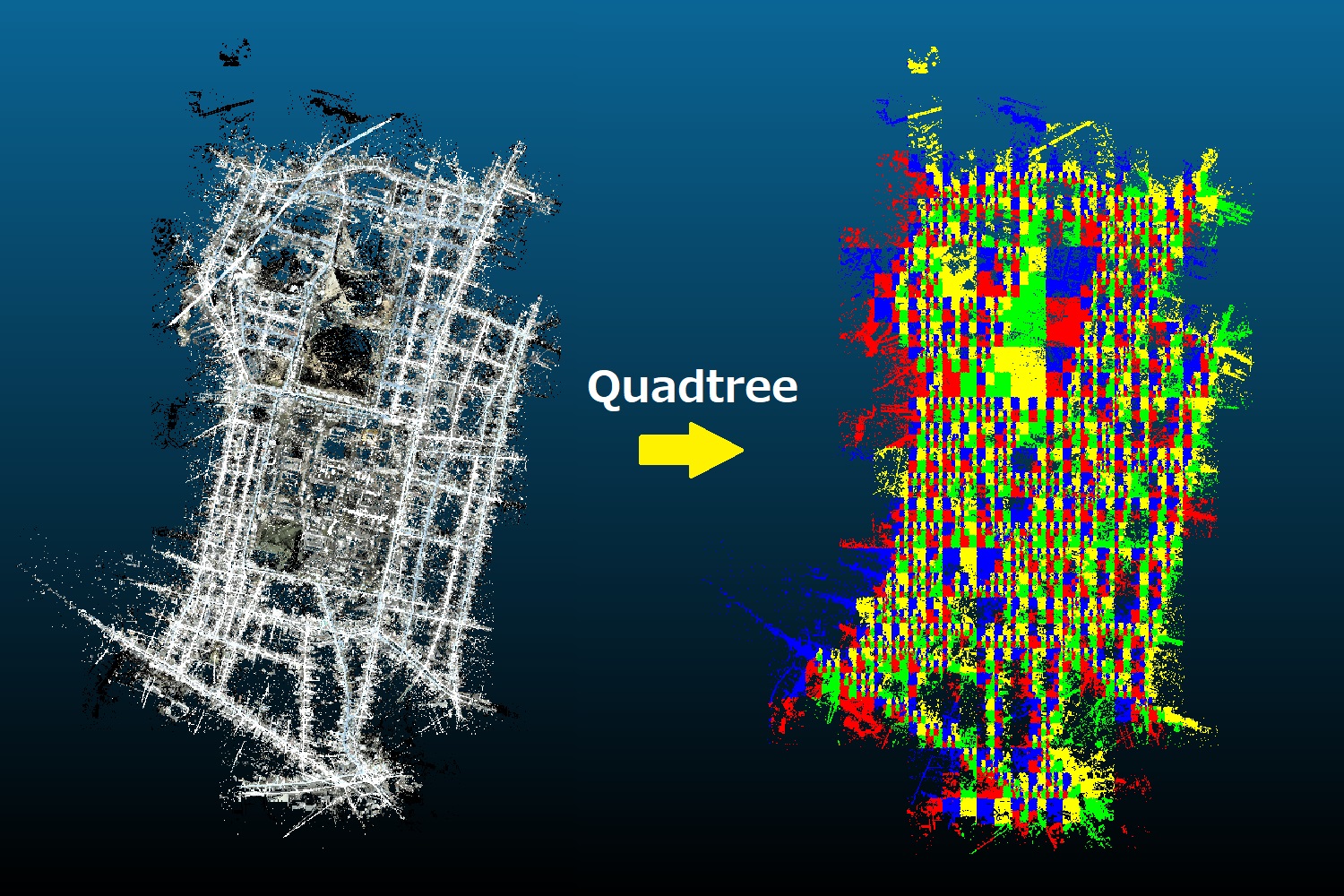
[P12] 大規模災害発生時における被災状況把握のための多重解像度データベースの構築
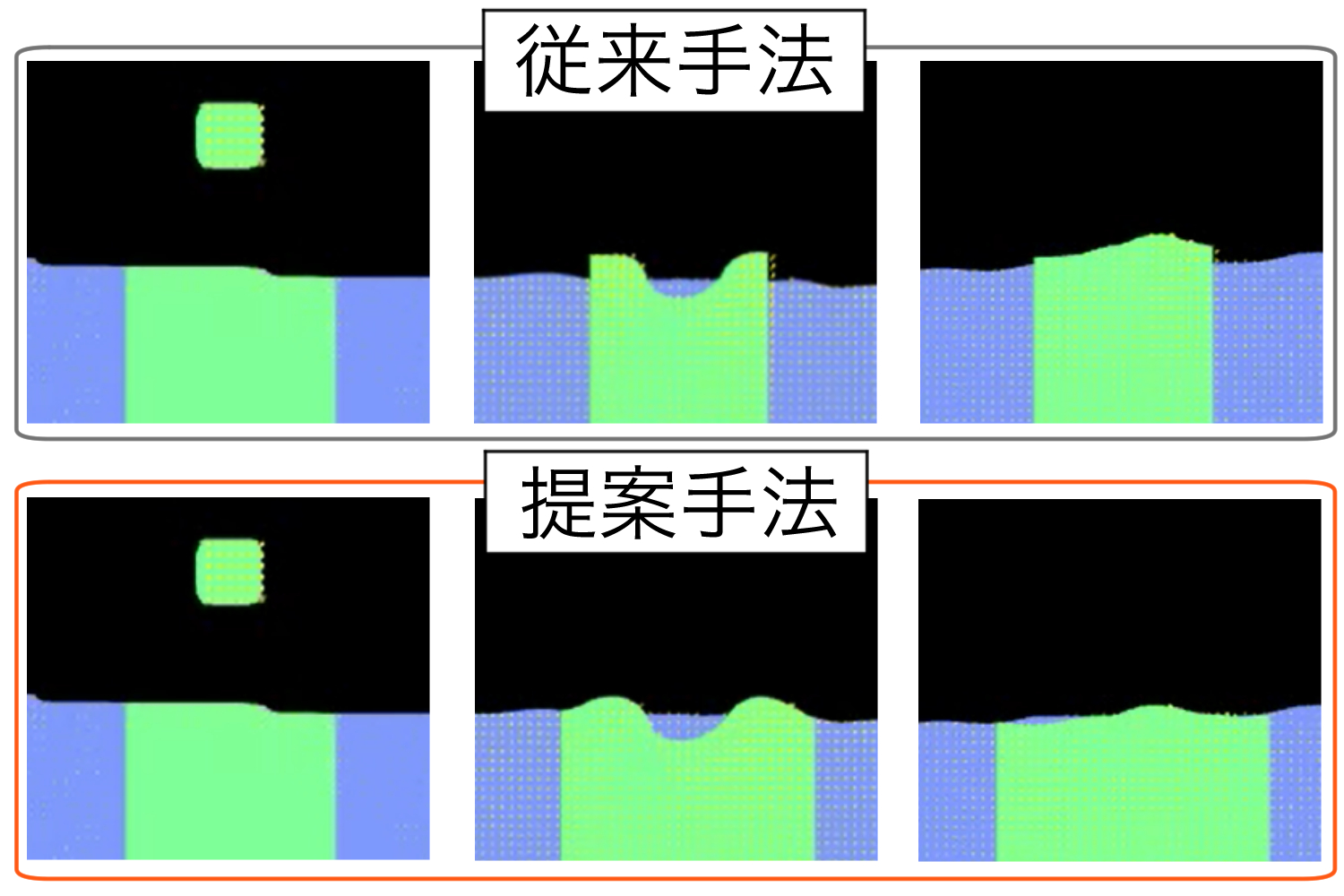
[P13] 液体の局所的な再シミュレーションにおける適応的な領域拡張

[P14] Loiterer Retrieval and Visualization using Entropy Model
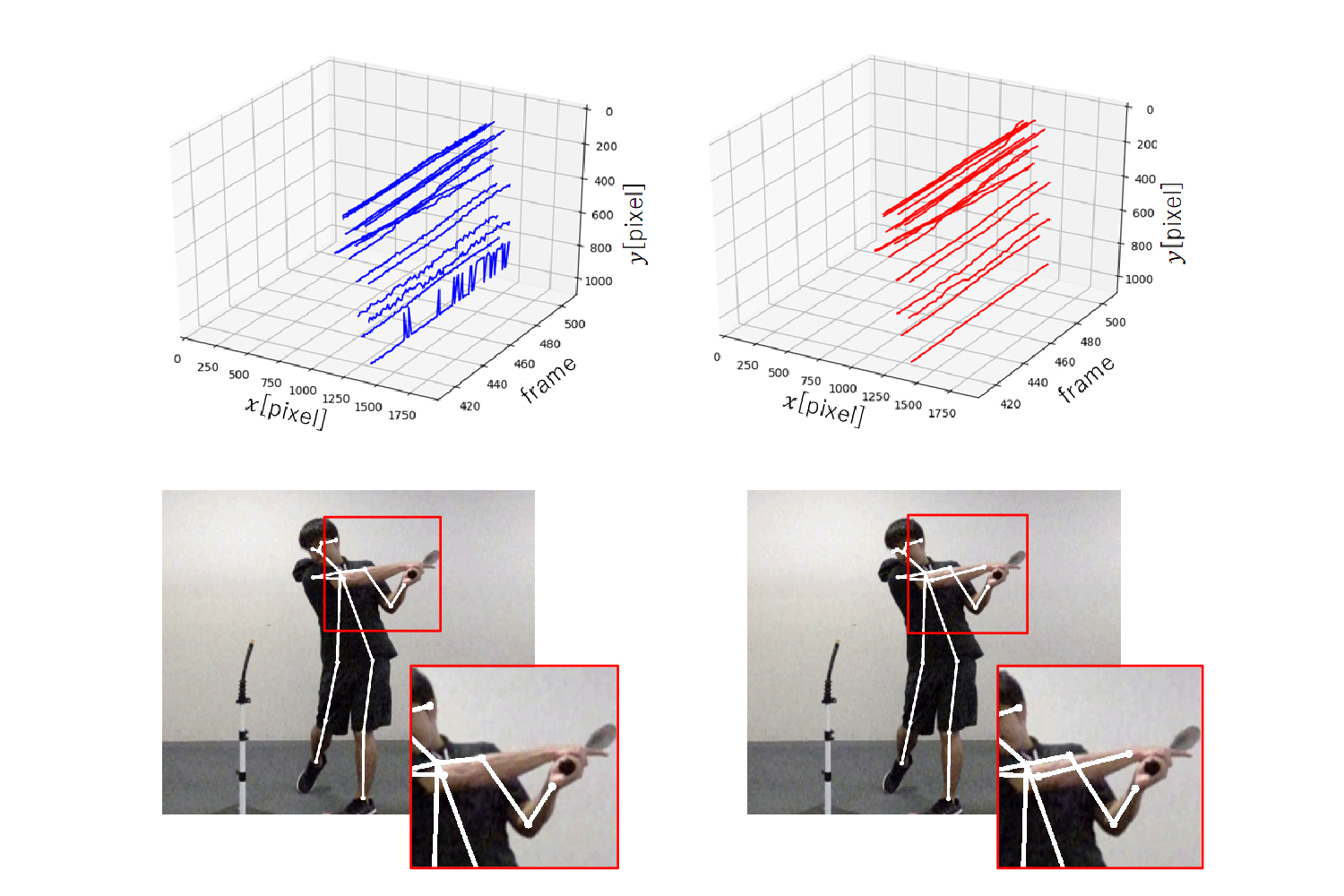
[P15] フレーム間の連続性を考慮した人物姿勢推定法の堅固化

[P16] アニメータ技法に基づく髪のなびきのデジタル再現

[P17] 3次元人体姿勢推定によるスポーツトレーニング支援

[P18] 格子細分割による布のよれ付与

[P19] ディジタルペンとドットスクリーンによる三次元CG筆記の顔美容における検討

[P20] スタイル変換技術を用いて写真をイラスト化するためのワークフロー

[P21] 深層学習を用いた任意画像に対するトーンカーブ推定

[P22] SVMによるアニメキャラクタの顔に対する作画崩壊の判別

[P23] 深層学習を用いた織物パターンのアーティファクト除去
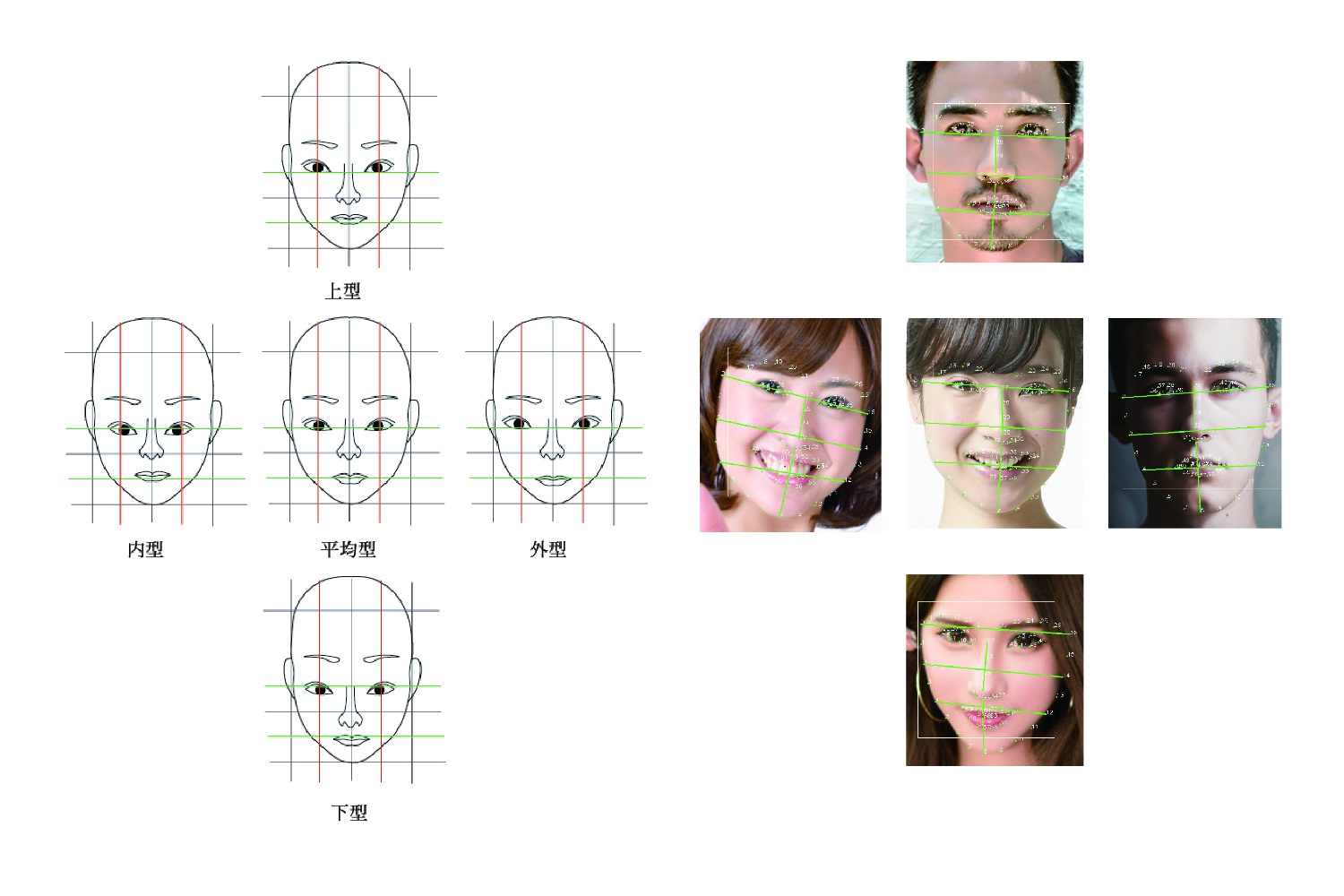
[P24] パーツ配置より似顔絵に対する類似度と誇張度の影響に関する検討

[P25] 線画キーフレームの 3 次元投影による対応線決定手法

[P26] ディープラーニングを用いたCGレンダリング手法が有する写実的表現能力の定量評価フレームワーク

[P27] 深層生成モデルを用いた顔方位変換画像生成手法

[P28] FCNによる文書画像の平面化処理ための領域分割に関する実験

[P29] 顔の特徴点に基づく手描きと3DCGアニメーションの顔の特徴比較
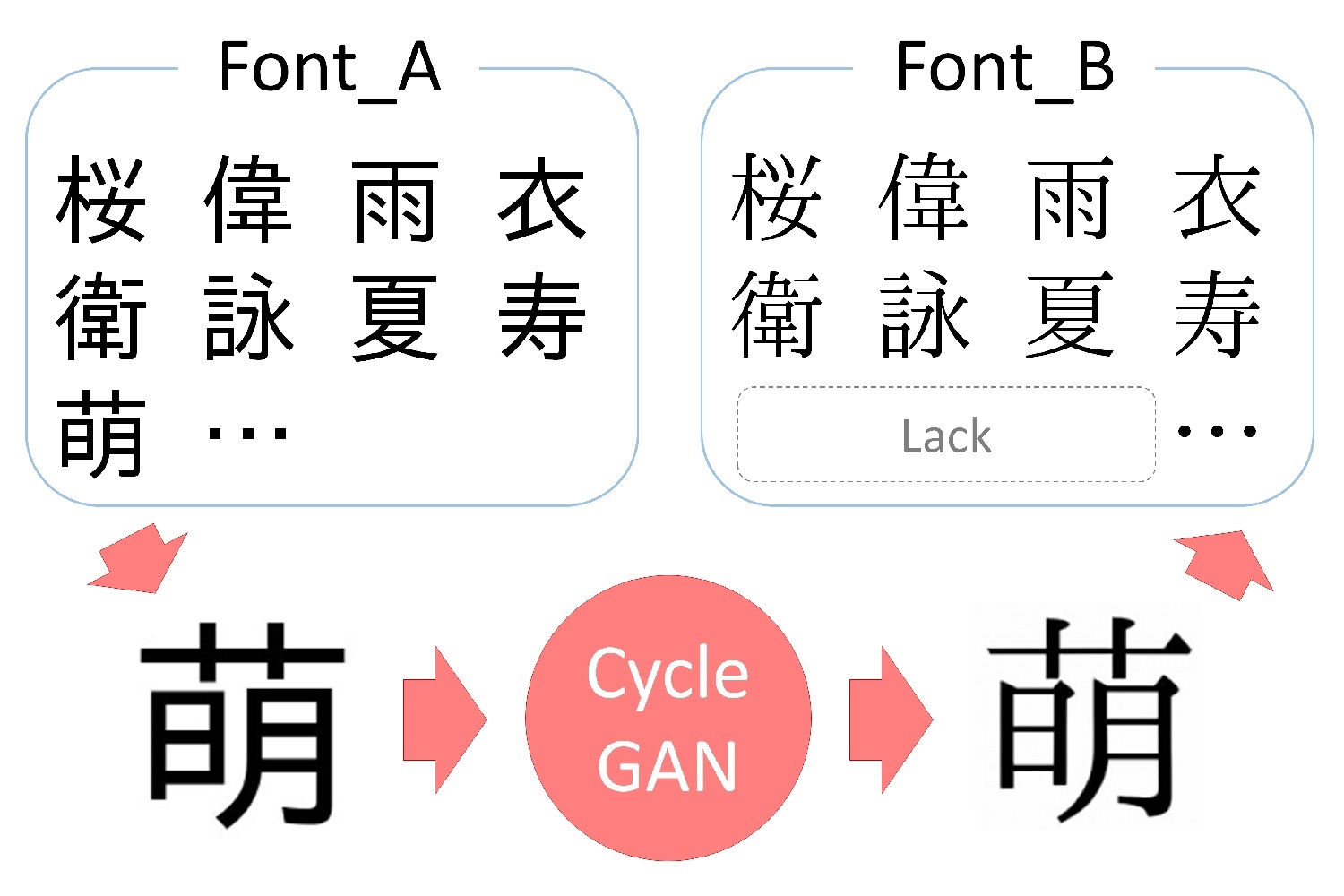
[P30] 対訳無し学習による和文フォント画像間のスタイル転写
![]()
![]()
![]()
![]()
![]()
 Twitter
Twitter
 Google+
Google+


