
[1] 保守的シャドウマップを用いたFrustum Traced Shadows の高速化

[2] 基本材質の拡散プロファイル混合による実測BSSRDFデータの圧縮

[3] スーパーサンプリングを用いた多光源レンダリングのための誤差推定法
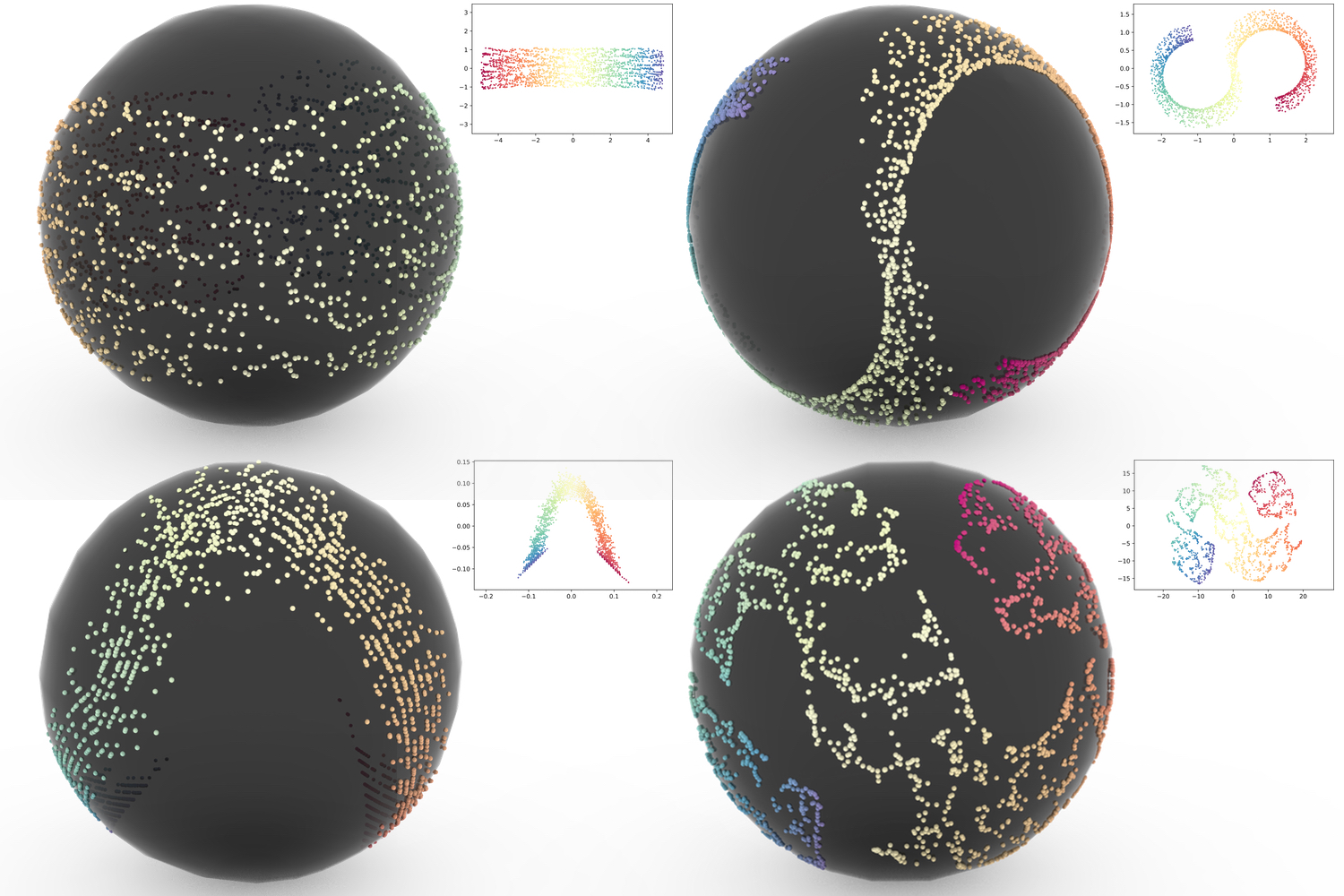
[4] 没入的VRデータ可視化のための球面への2次元プロットのマッピング
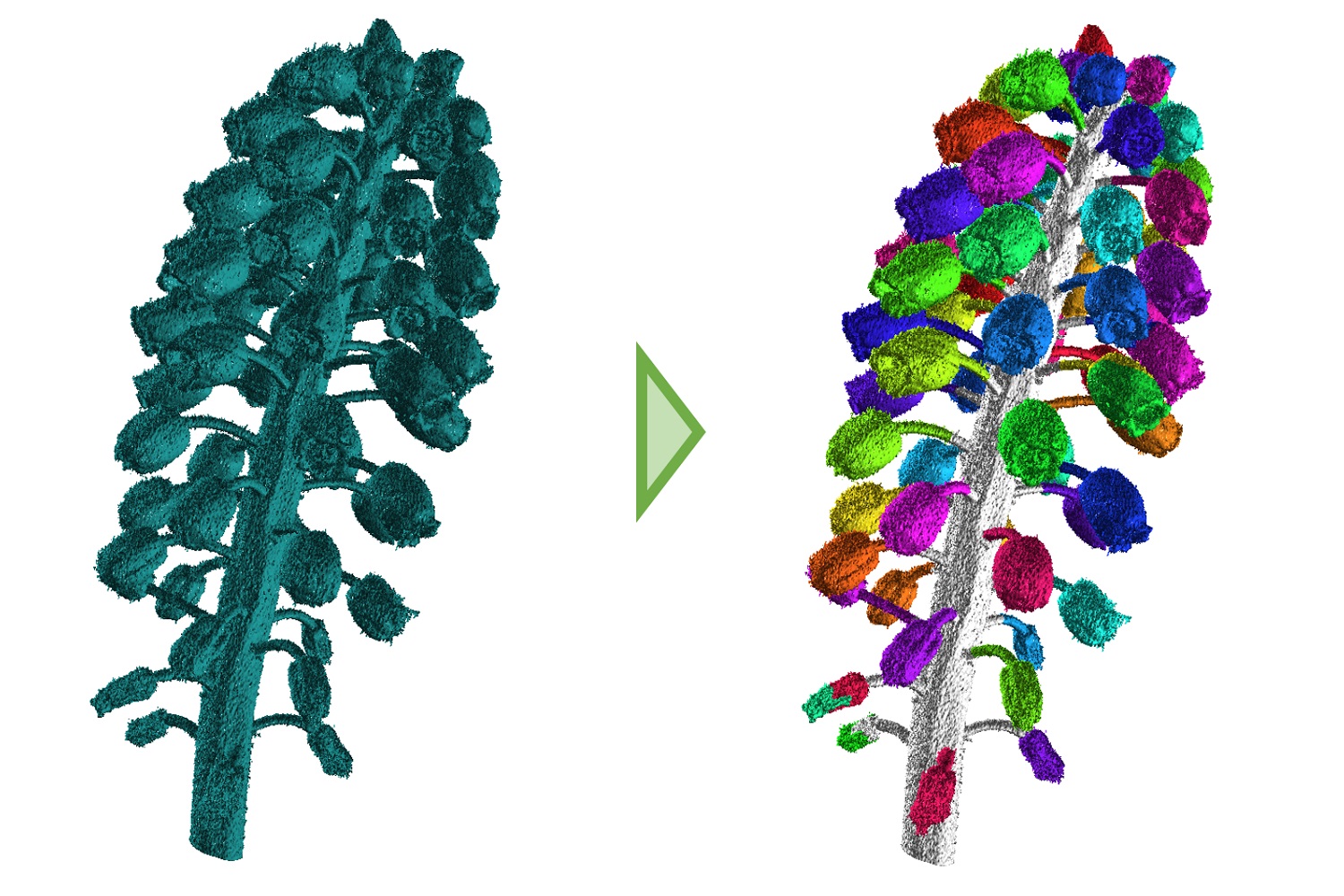
[5] 最小切断面を利用した2値画像の意味的領域分割
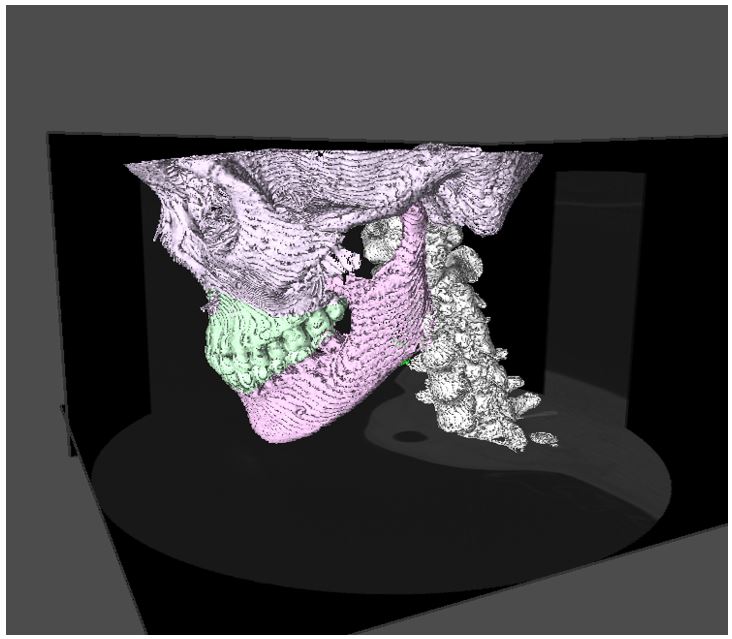
[6] 嚥下動作解析のための医用4次元画像領域分割ツールの開発 (応用論文)
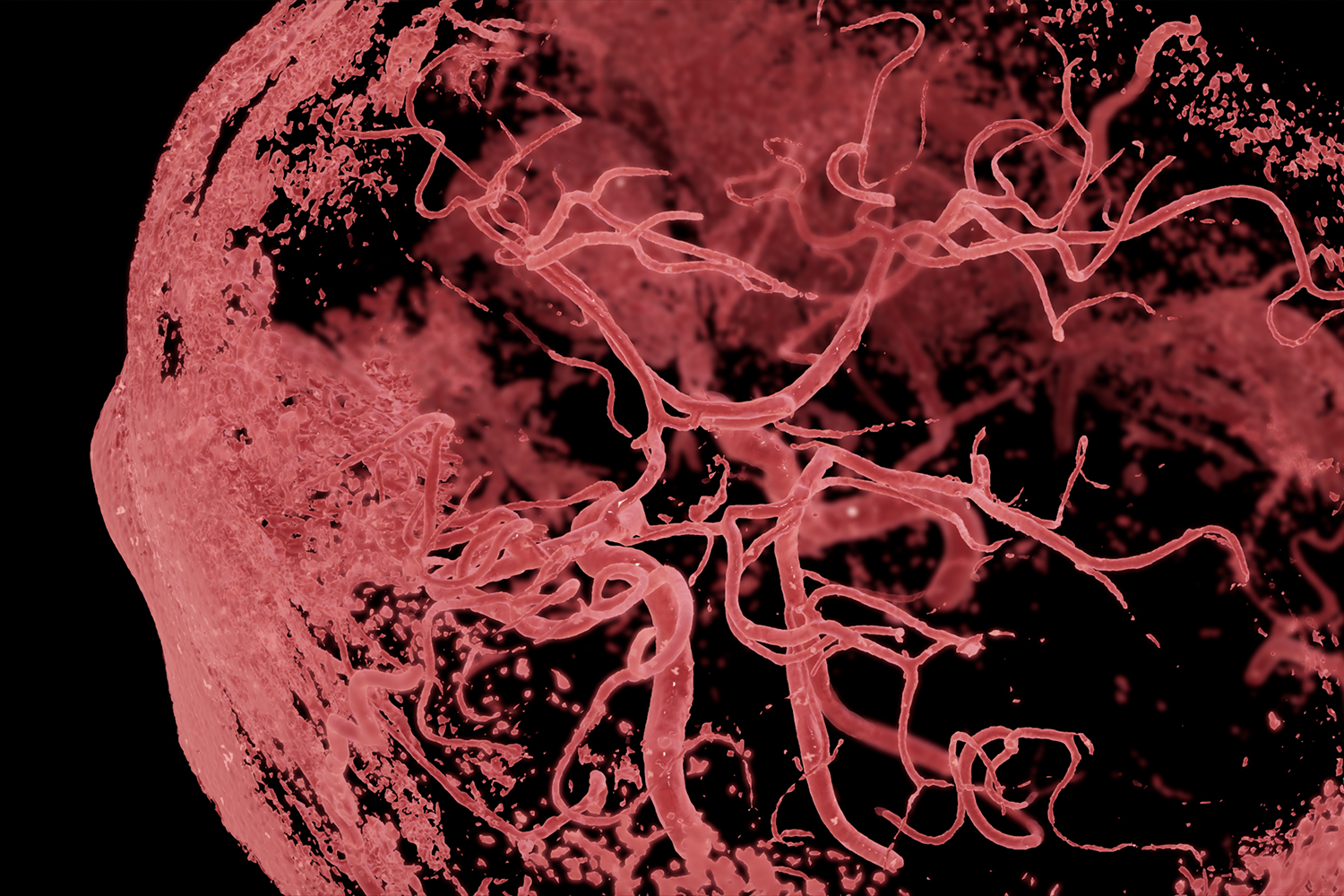
[7] 医用画像からの構造抽出における立体構造把握のための表現手法 (応用論文)
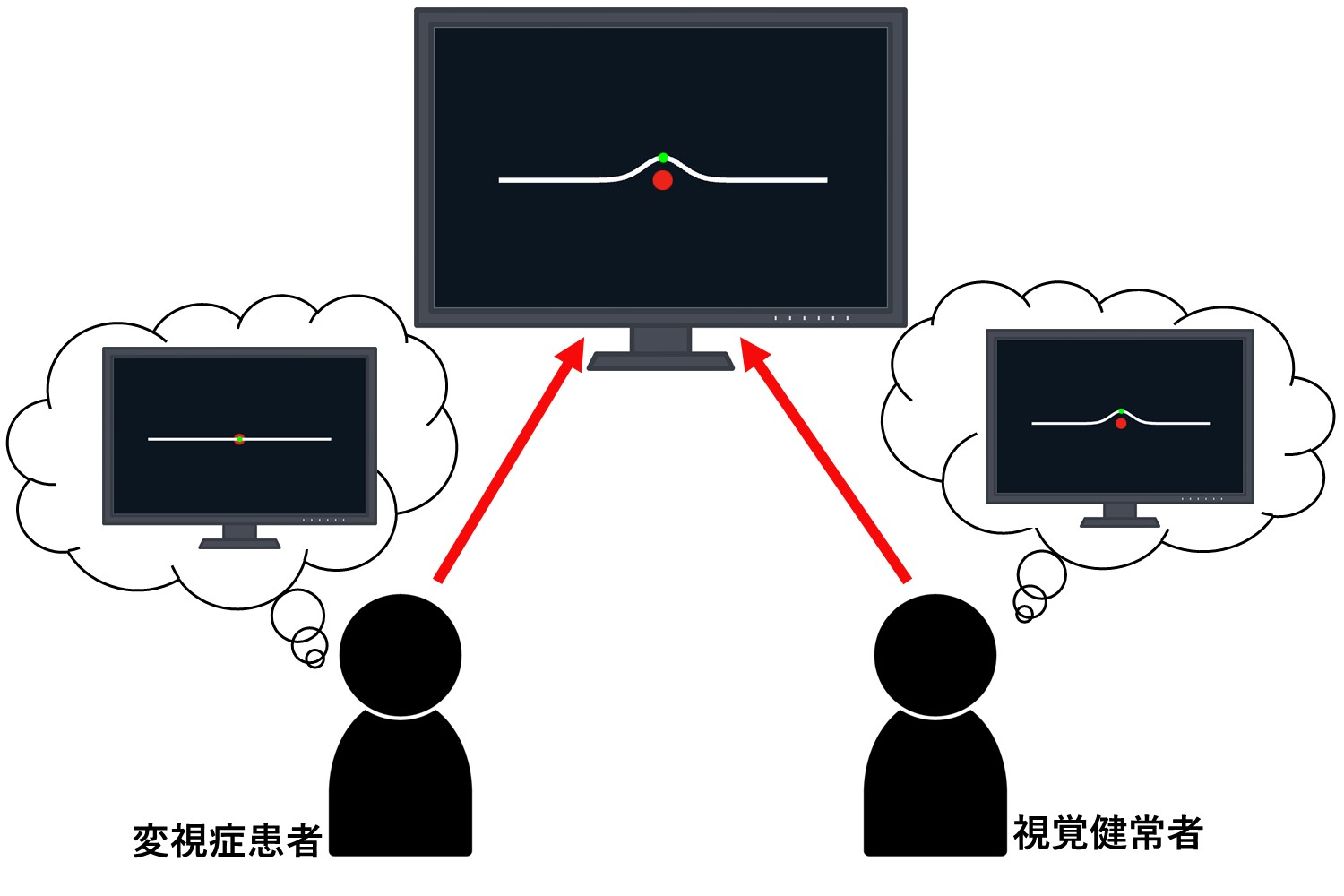
[8] 線変形操作を用いた変視症検査方法 (応用論文)

[9] Stochastic Light Culling (I3D 2017)

[10] Stochastic Light Culling for VPLs on GGX Microsurfaces (EGSR 2017)

[11] Distributed Optimization Framework for Shadow Removal in Multi-Projection Systems (EG 2017)

[12] Makeup Lamps: Live Augmentation of Human Faces via Projection (EG 2017)
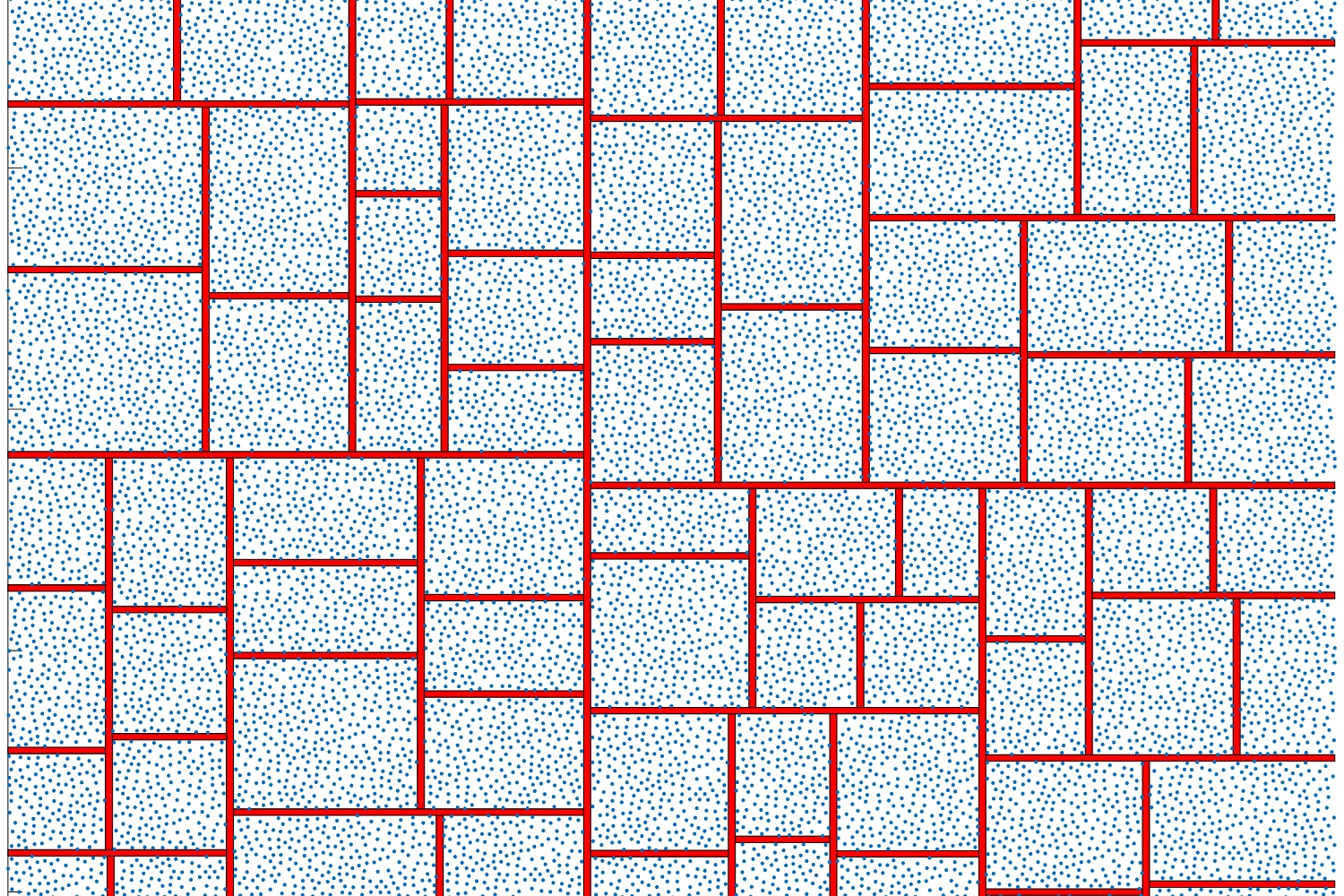
[13] Fast Generation of Maximal Poisson-Disk Samples with Randomized Tiling (HPG 2017)

[14] Narrow Band FLIP 法の拡張による効率の良い液体シミュレーション (EG 2018)

[15] OptiMo: 最適化計算を活用したキーフレームキャラクタモーション編集システム

[16] Deep Compact Motion Manifold に基づくモーションの生成と編集
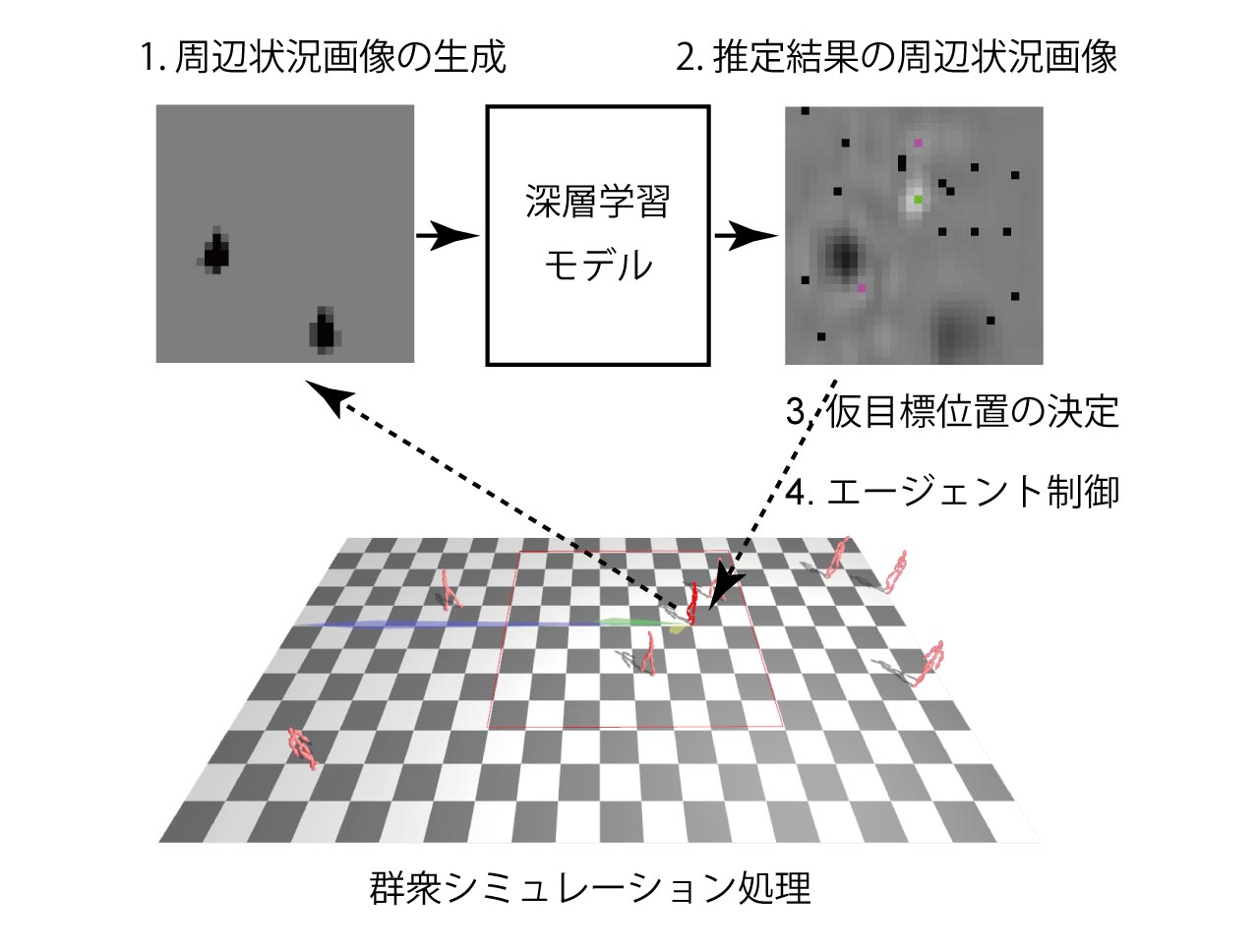
[17] 深層学習と周辺状況画像を用いた群集シミュレーションのためのエージェント移動制御

[18] 時間的一貫性を考慮した動画修復手法の高速化

[19] エピポーラ幾何に基づくPlane-to-Rayライトトランスポートの計測と解析

[20] 物体表面上の熱伝播と画像データベースを基にした時間経過により成長する水滴形状表現

[21] 側鎖結合を考慮した毛髪の塑性変形シミュレーション

[22] 大気中の音の伝播の高速計算
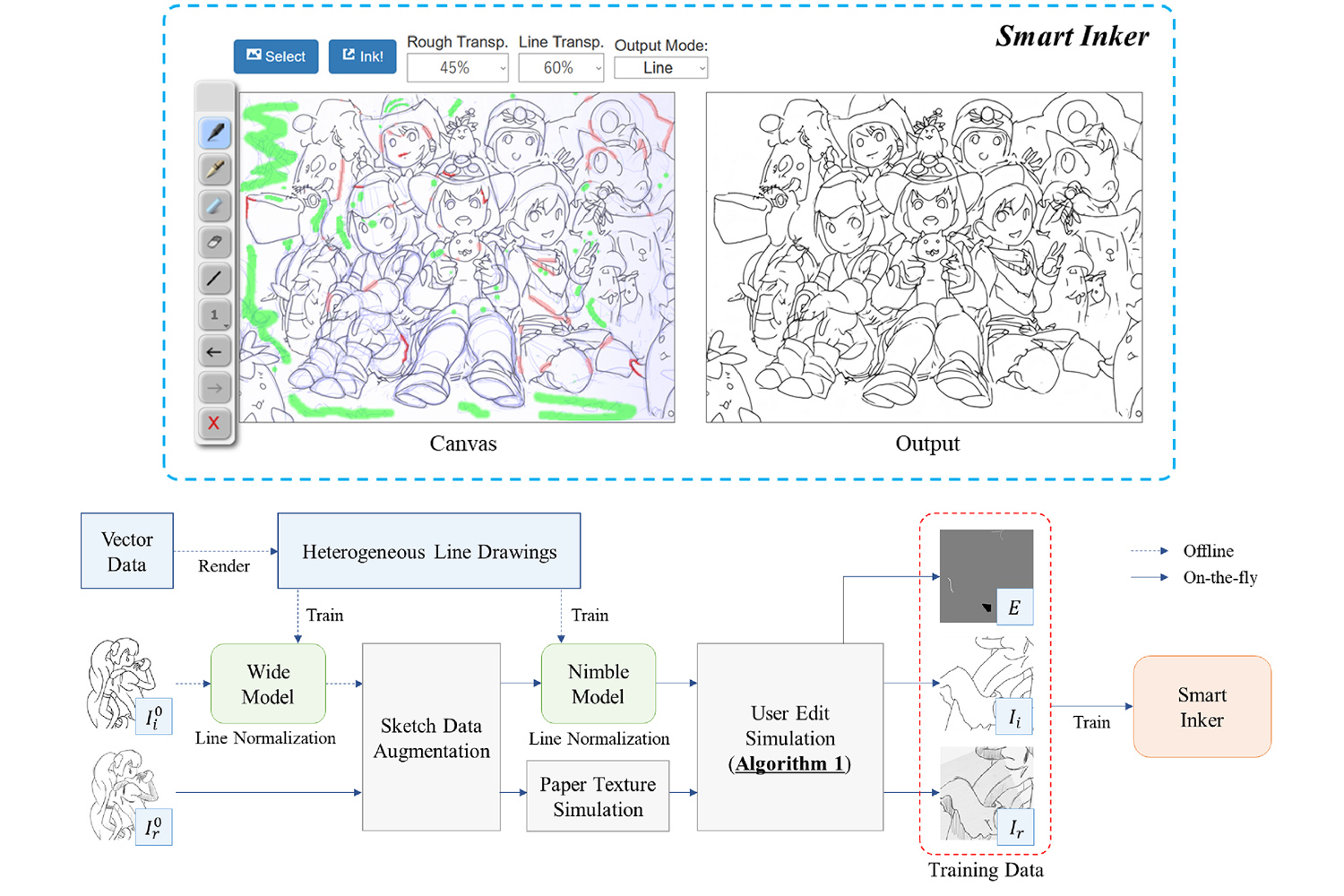
[23] Smart Inker: ラフスケッチのペン入れ支援

[24] 敵対的データ拡張による自動線画化 (TOG Paper)

[25] Gradient-domain Volumetric Photon Density Estimation

[26] 複数画像を表示する反射板の制作法

[27] 例示に基づく乱流のスタイル転写

[28] 流れの補間を用いた流体アニメーションの編集 (TOG Paper)

[29] 事前計算パネル法による空気力学モデル (TOG Paper)

[30] High-Fidelity Facial Reflectance and Geometry Inference from an Unconstrained Image
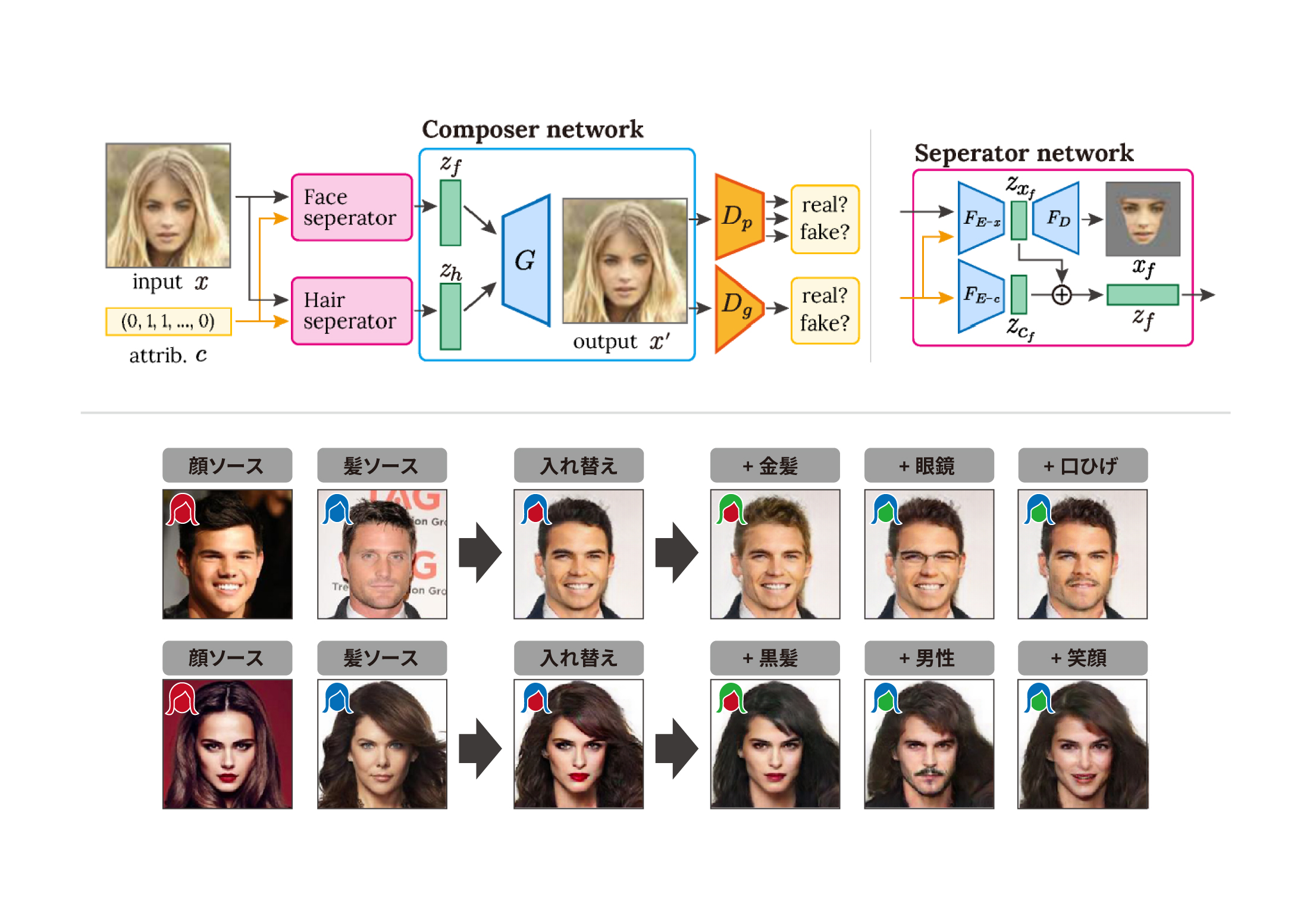
[31] 変分オートエンコーダを用いた領域特徴抽出による顔領域入れ替えを含む画像編集法

[32] 深層学習による顔魅力度評価を用いた化粧自動最適化

[33] 人物の単視点全身画像の再照明

[34] 自然さ保存とコントラスト強調を考慮した色覚補償のための色変換アルゴリズム

[35] 3次元形状を折りたたみ可能な立体へ半自動変換する手法の提案 (PG 2017)

[36] Deep Reverse Tone Mapping (SIGGRAPH Asia 2017)

[37] リアルタイムレンダリングに適した一枚画像からのアバター生成 (SIGGRAPH Asia 2017)

[38] Fully Perceptual-Based 3D Spatial Sound Individualization with an Adaptive Variational AutoEncoder (SIGGRAPH Asia 2017)

[39] Understanding and Exploiting Object Interaction Landscapes (SIGGRAPH 2017 (TOG Paper))
![]()
![]()
![]()
![]()
![]()
 Twitter
Twitter
 Google+
Google+


